
The client is a global leader in dental implant manufacturing and related digital technologies, producing vast volumes of structured and semi-structured operational data. They needed a unified and scalable data platform to support real-time decision-making and advanced analytics across multiple business domains.
The client sought to consolidate data from siloed systems into a single cloud-native architecture to enable timely insights into sales, product usage, and supply chain performance. Their existing system suffered from delayed data availability, high operational costs, and limited governance over data quality and access control.
– Migrating large volumes of structured data from SQL Server into a modern data lakehouse architecture
– Handling a mix of structured and semi-structured formats and applying consistent transformation logic
– Designing scalable, maintainable ETL workflows with strong observability and version control
– Ensuring security, role-based access, and compliance in a highly regulated environment
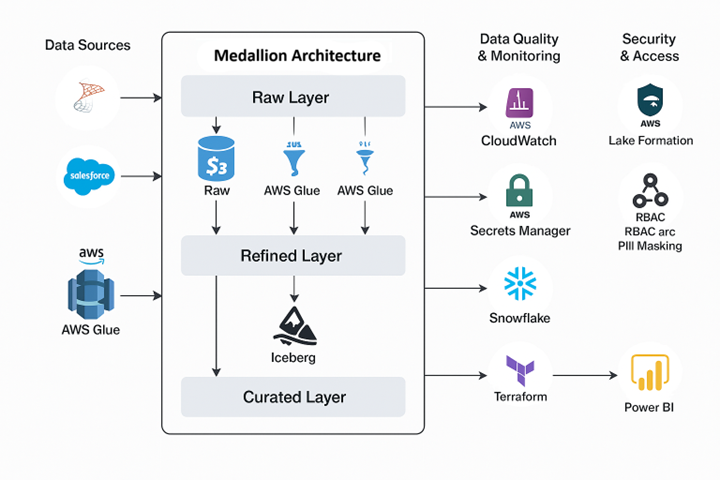
We implemented a medallion architecture (Raw → Refined → Curated) on AWS and Snowflake, leveraging Glue, Iceberg, and Athena for ETL. Data from SQL Server was first ingested via AWS DMS into S3 buckets (raw zone). AWS Step Functions triggered Glue jobs that transformed and loaded the data into refined and curated zones based on PySpark logic. Final data sets were modeled into star schemas and published to Snowflake for consumption in Power BI dashboards. This architecture improved reliability, observability, and data freshness.
– Partitioned Iceberg tables to improve query performance and reduce scanning costs
– Enabled compression and S3 lifecycle policies to optimize storage costs
– Tuned Glue job parallelism, memory allocation, and used bookmarks for incremental loads
– Right-sized Snowflake virtual warehouses based on workload intensity
– Integrated validation logic in PySpark jobs to check schema compliance and data completeness
– Used AWS CloudWatch and Glue logs to monitor job status, durations, and failures
– Future plans include integrating Great Expectations and Deequ for enhanced quality testing
– Enforced fine-grained access policies using AWS Lake Formation and Snowflake RBAC
– Secured connection secrets via AWS Secrets Manager
– Applied row-level access and PII masking in Snowflake for analytics users
All resources were provisioned using Terraform (IaC), including S3 buckets, Glue jobs, and Snowflake schemas. ETL logic and configurations were version-controlled in Git, with GitHub Actions used for testing and deployment. Parameterized transformation logic allowed changes to be rolled out safely across environments.
We designed Snowflake schemas using dimensional modeling (fact and dimension tables) to support high-performance BI workloads. Curated data sets were exposed to Power BI, enabling stakeholders to access near real-time insights from clean, governed data.